当我们谈到人工智能时,首先要了解一些最基本的概念和它的来历。所谓人工智能,无非就是用机器实现类似人的自主思考和判断决策能力。早在1956年,科学家们就在探讨能不能制造出一个可以像人类大脑的一样思考的机器,拥有人类的智慧,这就是人工智能。而实现人工智能的方法我们统称为“机器学习”。其实人类的行为是通过学习和模仿得来的。而机器学习,就是让机器和人类的学习行为一样,从历史数据和行为中不断学习和模仿,然后将规律应用到未来中,从而实现AI。自打机器学习这一方法论的提出,科学家们开始提出了各类各样的算法和去解决各种“智能”问题。但是随着研究的不断深入,传统机器学习算法在很多“智能”问题上效果不佳,无法实现真正的“智能”。2006年,突破点终于到来,加拿大多伦多大学教授Geoffrey Hinton对传统的神经网络算法进行了优化,在此基础上提出了Deep Neural Network的概念,引起了Deep Learning在学术界研究的热潮。这一将人工智能和机器学习带到了一个新高度的技术就是:Deep Learning(深度学习)。
深度学习是一种机器学习的技术,它是机器学习最重要的一个子集。当我们讨论人工智能时,就再也离不开深度学习技术了。
深度学习是基于神经网络算法的,上文也提到2006年Geoffrey Hinton老爷子提出了Deep Learning,核心就是人工神经网络算法。人类的大脑能实现纷繁复杂的计算和记忆,就完全靠900亿神经元组成的神经网络。那么生物神经网络是如何运作的了?
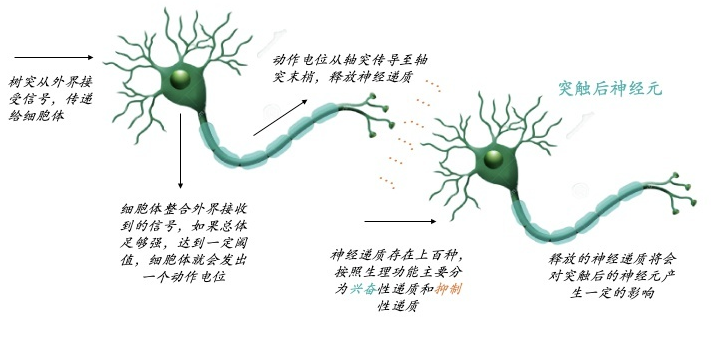
我们的大脑大约由900亿神经元构成,每个神经元大约与10,000个其它神经元连接。通过神经元接收外界信号,达到一定阈值,触发动作电位,通过突触释放神经递质,可以是兴奋或抑制,影响突触后神经元。通过此实现大脑的计算、记忆、逻辑处理等,进行做出一系列行为等。同时不断地在不同神经元之间构建新的突触连接和对现有突触进行改造,来进行调整。有时候不得不感叹大自然的鬼斧神工,900亿神经元组成的神经网络可以让大脑实现如此复杂的计算和逻辑处理。
科学家们从生物神经网络的运作机制得到启发,构建了人工神经网络。最经典的神经元模型,是1943年由科学家McCulloch和Pitts提出的,所以通常称MP神经元模型,他们将神经元的整个工作过程抽象为下述的模型。
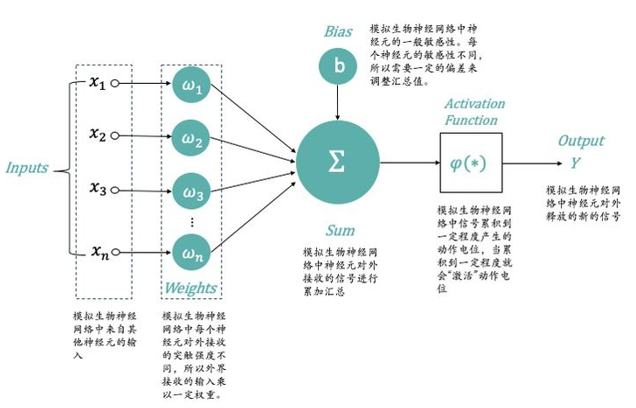
最早的MP神经网络实际应用的时候因为训练速度慢、容易过拟合、经常出现梯度消失以及在网络层次比较少的情况下效果并不比其他算法更优等原因,实际应用的很少。中间很长一段时间神经网络算法的研究一直处于停滞状态。人们也尝试模拟人脑结构,中间加入更多的层”Hidden Layer“隐藏层,和人脑一样,输入到输出中间要经历很多层的突触才会产生最终的Output。加入更多层的网络可以实现更加复杂的运算和逻辑处理,效果也会更好。这也是“深度”一词的由来。但传统的Back Propagation训练方式在层数较多的神经网络训练上不适用,经常会收敛到局部最优上,而不是整体最优。另外当人们加入更多的”Hidden Layer“时,如果对所有层同时训练,计算量太大,根本无法训练;如果每次训练一层,偏差就会逐层传递,最终训练出来的结果会严重欠拟合(因为深度网络的神经元和参数太多了)。
一直到2006年,Geoffrey Hinton提出了一种新的解决方案:无监督预训练对权值进行初始化+有监督训练微调,从而使深度学习发展到新的高度。
总结一下:深度学习的概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习中最著名的卷积神经网络CNN,在原来多层神经网络的基础上,加入了特征学习部分,这部分是模仿人脑对信号处理上的分级的。具体操作就是在原来的全连接的层前面加入了部分连接的卷积层与降维层,而且加入的是一个层级。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。
- 深度学习框架
在了解了深度学习和神经网络以后,相信大家也经常听到如下的英文单词:Tensorflow、Caffe、Pytorch等,这些都是做什么的了。Tensorflow是Google旗下的开源软件库,里面含有深度学习的各类标准算法API和数据集等,Pytorch是Facebook旗下的开源机器学习库,也包含了大量的深度学习标准算法API和数据集等。Caffe是贾扬清大神在UC Berkeley读博士时开发的深度学习框架,2018年时并入到了Pytorch中。
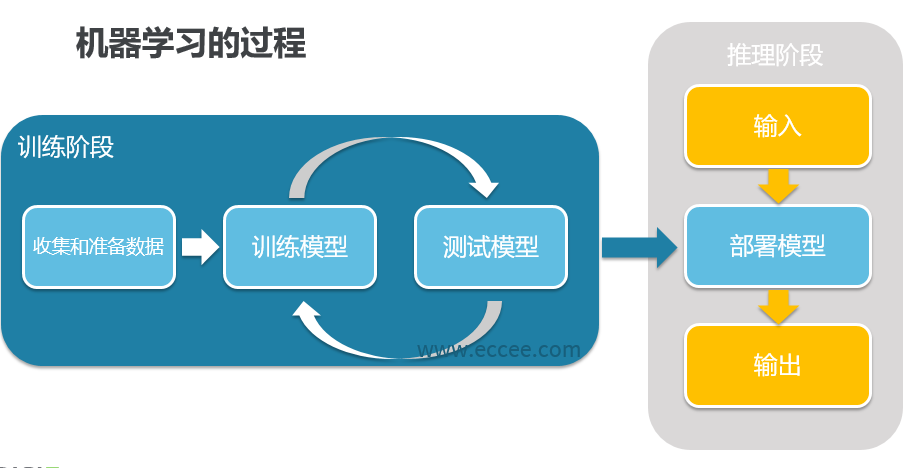
一个完整的深度框架中应该包含两个主要部分,即训练(training)和推理(inference)
训练(Training)
打个比方,你现在想要训练一个能区分苹果还是橘子的模型,你需要搜索一些苹果和橘子的图片,这些图片放在一起称为训练数据集(training dataset),训练数据集是有标签的,苹果图片的标签就是苹果,橘子亦然。一个初始神经网络通过不断的优化自身参数,来让自己变得准确,可能开始10张苹果的照片,只有5张被网络认为是苹果,另外5张认错了,这个时候通过优化参数,让另外5张错的也变成对的。这整个过程就称之为训练(Traning)。
推理(Inference)
你训练好了一个模型,在训练数据集中表现良好,但是我们的期望是它可以对以前没看过的图片进行识别。你重新拍一张图片扔进网络让网络做判断,这种图片就叫做现场数据(live data),如果现场数据的区分准确率非常高,那么证明你的网络训练的是非常好的。我们把训练好的模型拿出来遛一遛的过程,称为推理(Inference)。
部署(deployment)
想要把一个训练好的神经网络模型应用起来,需要把它放在某个硬件平台上并保证其能运行,这个过程称之为部署(deployment)。
因为深度学习发展至今,很多算法都已经是通用的,而且得到过验证的了。那么有些公司就希望将一些标准算法一次性开发好,封装起来,后面再使用时直接调用引入即可,不需要再写一遍。就像大家小时候学习英文一样,英文字典有牛津版本的,也有朗文版本的。对于收录的英文单词,英文单词如何使用,如何造句等,已经有了标准的用法。我们只需要查阅这些字典即可,而Tensorflow、Caffe、Pytorch做的其实也就是计算机届的牛津、朗文英文大词典。国内百度目前也有自己的深度学习框架Paddle-Paddle。
目前一般是学术界用Pytorch较多,Pytorch更适合新手入门,上手快。工业界用Tensorflow较多,更适合工业界的落地和部署等。深度学习应用最广泛的就是传统机器学习算法解决不了的领域或者是效果不佳的领域:视觉、自然语言和语音识别领域。
机器学习对计算能力的村求,也使得传统的CPU进行训练达到了极限,可能训练几个月都训练不出来结果。由于GPU很适用于神经网络算法的计算,因此很多机器学习框架也支持同时用GPU来进行运算。无论如何,要想进行高效的边缘计算,对本地CPU、GPU的处理能力不断提出了新的要求,以至于出现了专门用于神经网络运算的NPU。实际应用上,TOPS是一个重要的算力指标,它是指Trillion Operations per Second,即每秒可进行多少万亿次操作。比如Google的Coral TPU运算能力达4.0 TOPS。